Every AI Call
Can Teach You Something.

yasser
Admin · yasser's Individual Org
Traces
Every trace-create event lands here in real time.
Select trace
Filters
No filters applied. Add one to narrow your traces.
| Timestamp | Name | Level | Env | User | Session | Input | Tags | Latency | Obs | Tokens | Output | Cost |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Jun 23, 03:18 PM | chat-turn | OK | production | user-184 | sess-7b2 | summarize refund policy | support, prod | 842 ms | 2 | 1.3k | The refund window is 30 days... | $0.0018 |
| Jun 23, 03:16 PM | rag-answer | WARNING | production | user-092 | sess-a19 | compare enterprise plans | rag, pricing | 2.4 s | 4 | 3.8k | The Pro tier includes... | $0.0069 |
| Jun 23, 03:14 PM | openai.chat.completions | OK | staging | qa-12 | sess-41f | draft onboarding reply | 690 ms | 1 | 884 | Welcome aboard. Here are... | $0.0009 | |
| Jun 23, 03:11 PM | support-agent | ERROR | production | user-318 | sess-c03 | change my billing email | agent, tool | 5.8 s | 5.1err | 5.6k | tool timeout: crm.updateUser | $0.0112 |
| Jun 23, 03:08 PM | eval-run | OK | production | system | eval-22 | score answer relevance | evals | 1.1 s | 3 | 2.1k | score: 0.91 | $0.0034 |
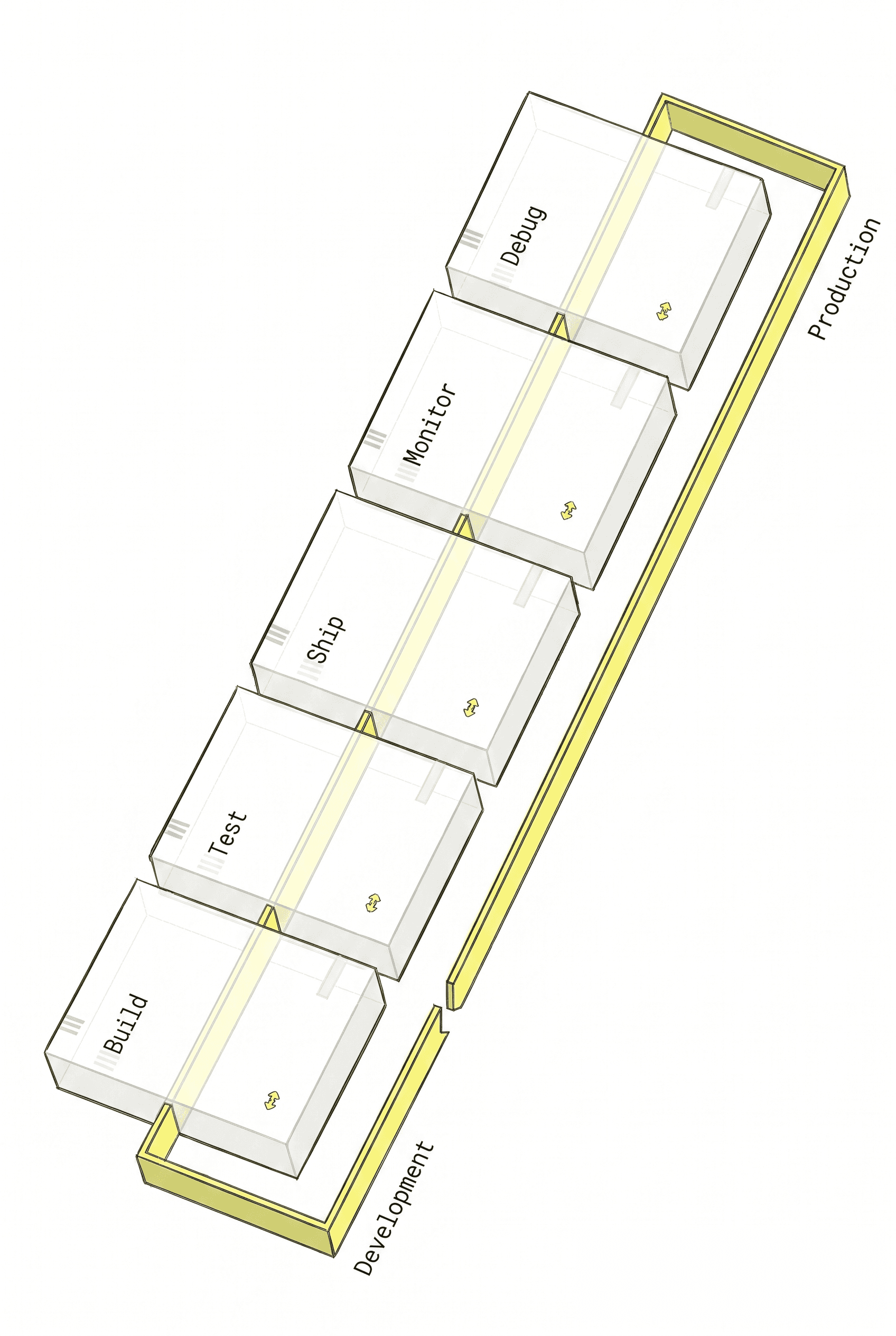
Ship quality AI at scale

Observability
Capture every LLM call, tool execution, and retrieval step in hierarchical traces. Filter by user, session, latency, cost, or custom metadata.

Evaluation
Evaluate outputs with LLM judges, custom heuristics, or human review. Run evaluations on production traffic or prompt experiments
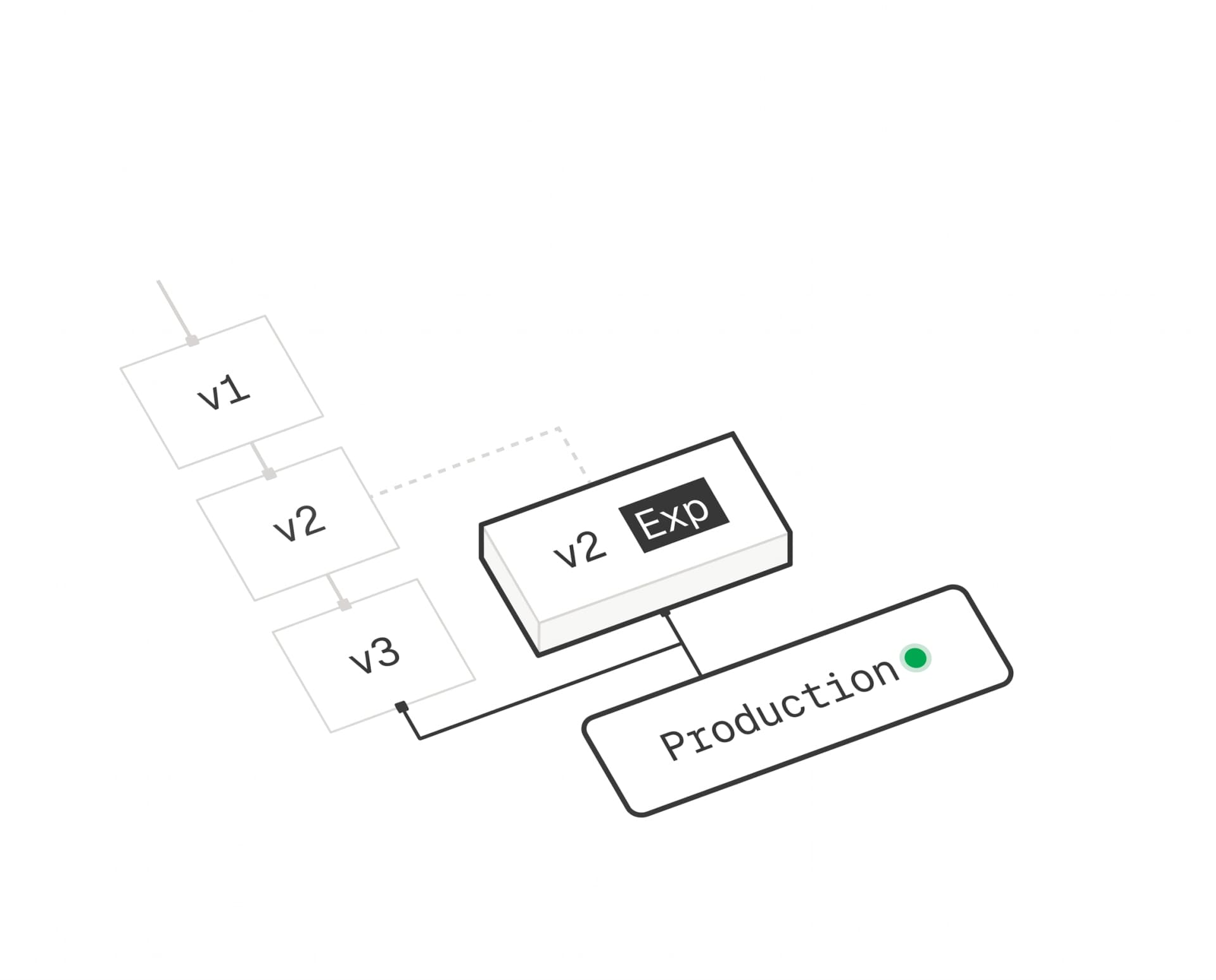
Prompt Management
Manage prompts outside your codebase with one-click deployments and rollbacks. Collaborate on prompt improvements with your entire team
Everything You Need to Improve Your AI
From production traces to prompt experiments, Currai gives your team one place to measure, test, and improve every AI interaction.
When you need to
Understand why an AI response failed
“Search disconnected logs and try to reconstruct what happened.”
The retrieval step timed out after 4.2s, leaving the model without context. The failing span and its inputs are ready to inspect.
When you need to
Measure the quality of production responses
“Manually review a small sample and rely on intuition.”
Evaluation complete: 91% passed. The 23 low-scoring responses are grouped and ready for review.
When you need to
Know which prompt performs better
“Deploy a new prompt and hope the results improve.”
Version B improved quality by 18% and reduced token usage by 12%. It is ready to promote.
When you need to
Update a prompt without redeploying your app
“Edit hard-coded prompts, open a pull request, and redeploy.”
Version 12 is live. Previous versions remain available for an instant rollback.
When you need to
Test a prompt before sending it to production
“Copy inputs between scripts and compare outputs manually.”
The strongest prompt and model combination is identified using real inputs and consistent scores.
When you need to
Find what is making your AI slow or expensive
“See one total duration and a monthly provider bill.”
Repeated tool calls account for 31% of cost, while retrieval adds 5.1s to the slowest requests.
Launch, observe, improve — repeat.
(and better!)Runner seamlessly integrates with the tools you already rely on, streamlining your workflow and ensuring that tasks are completed efficiently and effectively. It takes care of the details so you can focus on what truly matters.
Concurrent Runners
Run multiple tasks in parallel. Draft follow-ups while pulling analytics while updating your CRM. Receipts and timestamps for everything.
Local + Cloud
Works across your local machine and cloud services. Manages files, apps, and workflows wherever they live. Your data stays yours.
Memory Across Sessions
Runner remembers what matters across sessions: your contacts, your preferences, your unfinished work. Context that compounds over time.
Ship AI. Improve continuously
(and better!)AI drifts and regresses silently. With patterns surfaced automatically, the best teams can evaluate against expectations and iterate continuously
Connects to the stack you already use
CURRAI GUIDES
CURRAI GUIDES
Learn what Currai makes possible
Start with practical posts on tracing, evals, prompts, cost, and agent workflows so you know what to instrument first.
Pricing that tracks real volume
Starter
Free to get started.
$0/mo
50 MB included
3-day retention
- Drop-in Python & TypeScript SDKs
- Full traces, tokens & cost in one view
- Langfuse & OpenTelemetry compatible
Pro
For teams shipping to production.
$8/mo
2 GB included
14-day retention
- Everything in Starter
- Run evals and A/B test prompt versions in production
- Sessions & users roll-ups
- Cost, token & latency dashboards
Business
Higher volume, longer history.
$20/mo
4 GB included
30-day retention
- Everything in Pro
- Hosted ingestion, storage & dashboards
- Priority support
Need a custom plan?
Higher volume, longer retention, or specific terms — tell us about your usage and we'll tailor a plan to fit.